需要的技术:Python、Flask、requests、BeautifulSoup
前言
很久之前有接触过人家写的【快捷指令-下载小红书无水印图片】
当时觉得「快捷指令」很厉害!就点进去研究一下,发现根本看不懂。
后来接触多了 Python爬虫 🦎,其实无水印图片下载只是用 requests 请求网页版的小红书然后用 BeautifulSoup 解析网页找到图片链接,再用 requests 请求图片链接就可以下载图片了。由于网页版里的图片本身没有带水印,所以下载下来的图片就是无水印的了。
「快捷指令」只是把手机复制小红书的分享链接后把分享链接中的URL提取出来,然后给到电脑处理下载后,或者提取图片链接返回给手机的「快捷指令」,「快捷指令」再根据链接保存到手机相册就可以了。
所以我们的思路很简单:
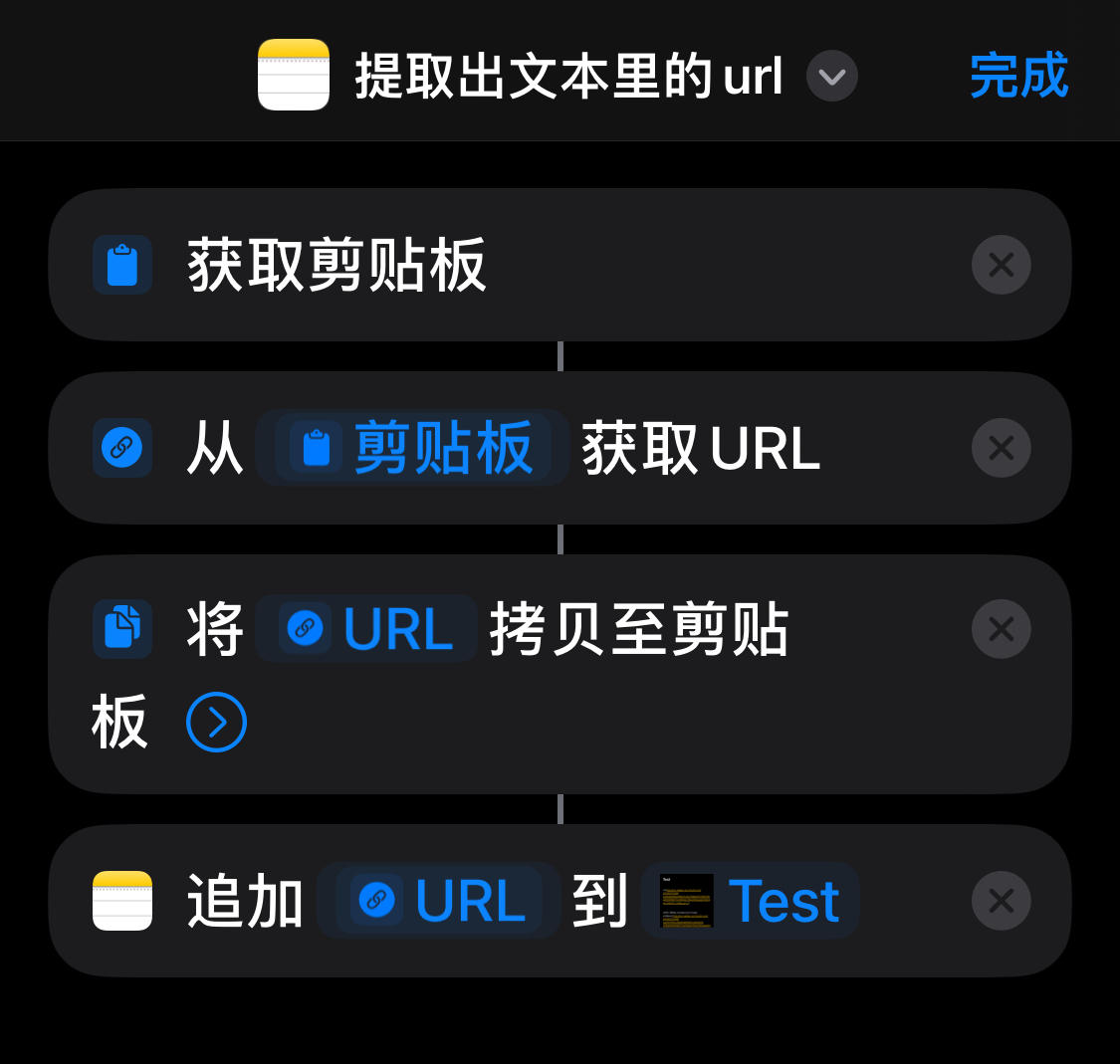
- iPhone 使用「快捷指令」从小红书的 “复制链接” 中提取 “URL” ,这个 “URL” 就是小红书的网页版链接。把这个网页链接发送给电脑(电脑搭建一个服务接收)。
- 本地电脑用 Python 的 Flask 框架搭建一个服务,监听一个端口,接收到这个“URL”后,用 Python 的 requests 模块请求这个链接,然后用 BeautifulSoup 模块解析网页,找到图片的链接。
- 获取 图片链接 后可以用本地电脑下载图片或把图片链接发给手机的「快捷指令」,让手机的「快捷指令」去下载图片。
那接下来,来看看基本的小操作吧。然后后面再一点一点去优化吧!
「快捷指令」提取URL
首先我们思路先是在小红书中,复制链接 🔗:
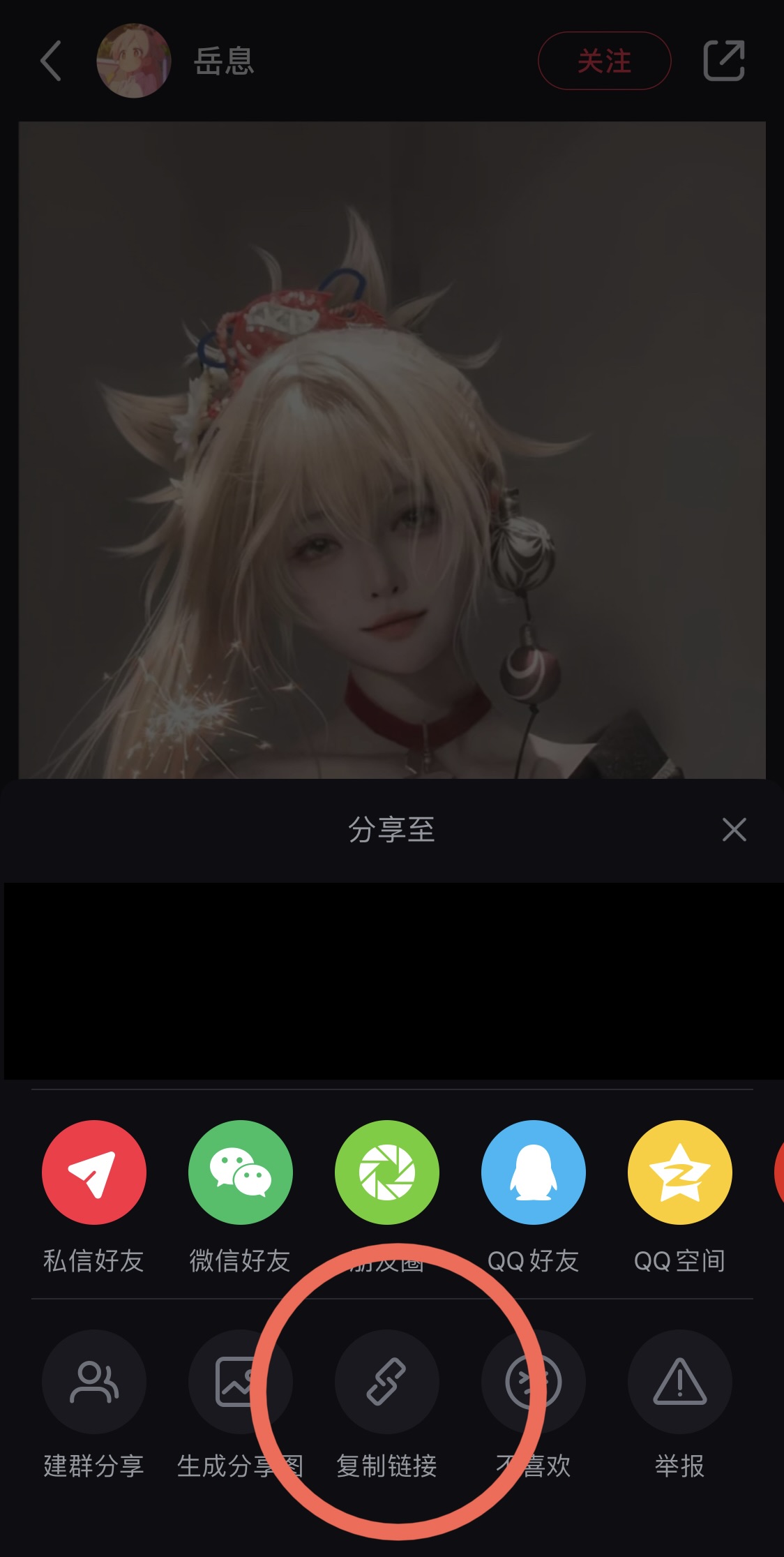
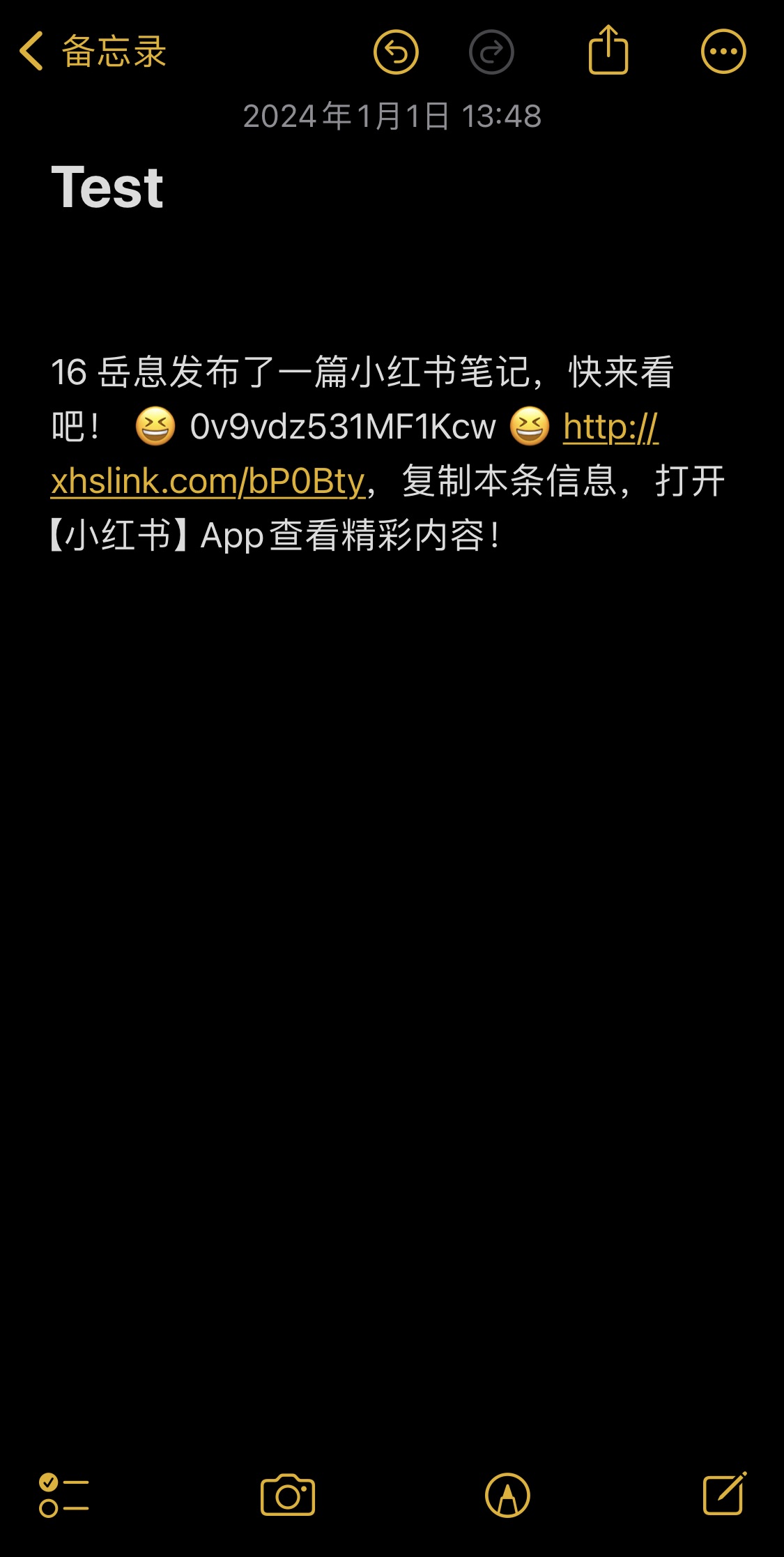
 只要同意后我们就可以轻松获得这其中的 URL 链接,这个链接其实就是小红书的网页版
只要同意后我们就可以轻松获得这其中的 URL 链接,这个链接其实就是小红书的网页版 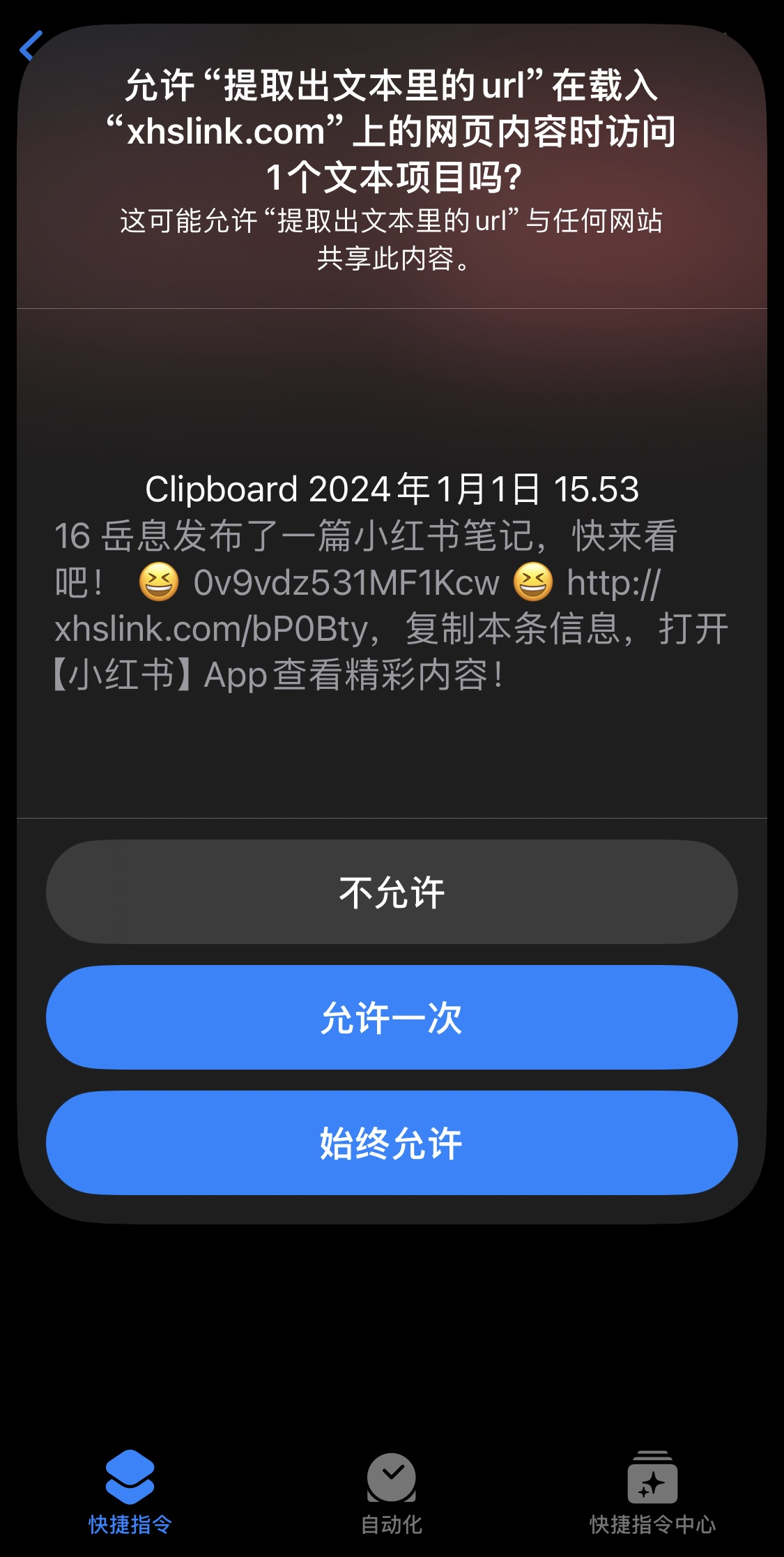
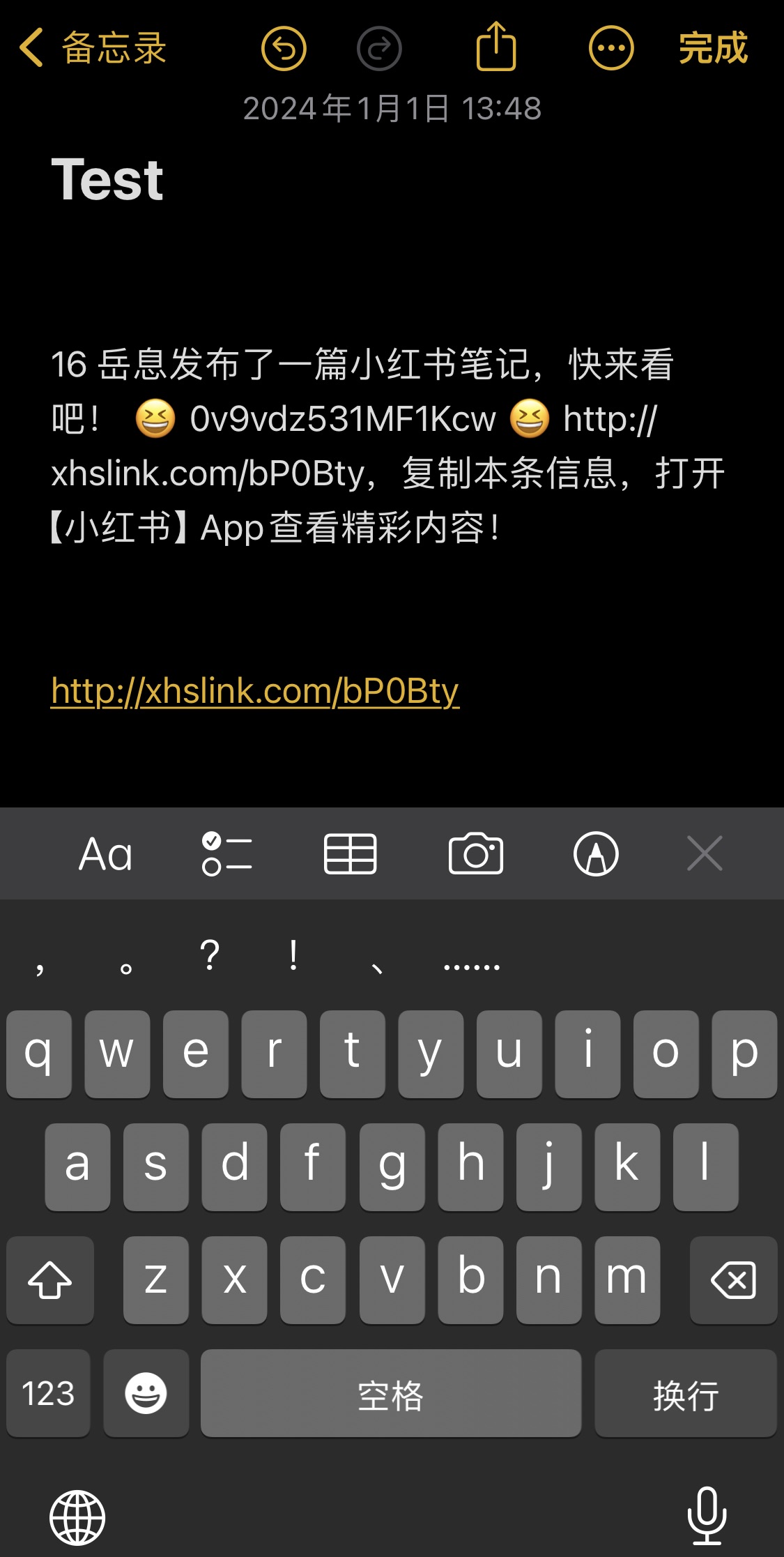
获取 URL链接 后,再把 URL链接 推送给服务器,或是家里的电脑来处理。
「Flask」接收URL
我们接下里的操作是:
- 用Python搭建起一个服务:Flask 应用
- 它会监听一个端口,通过这个端口来获取到这个图片链接
- 然后让 Python 爬虫爬取出图片链接
- 有了图片的链接
- 在电脑上自动下载
- 或是把链接推送回给手机,让手机去下载就好了。
- 下载python
- 在终端下载 Flask:
pip3 install Flask
我们在本地电脑 VSCode 写一个 app.py 👇
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/xhs', methods=['POST'])
def process_url():
# 获取JSON数据
data = request.json
url = data.get('url')
# 返回结果
return jsonify({'result': url})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5001)
这上面写完,用 python3 app.py 或者 python app.py 来启动这个脚本,它会监听本地5001端口服务。
- 关于本机ip地址:
127.0.0.1 - 但局域网里关于自己电脑的ip地址,每个人电脑都是不一样的,比如我的就是
192.168.254.110。 - 后面的5001是端口号,可以自己改。
- 所以我们的服务就搭建在
192.168.254.110:5001/xhs上,记得要用POST请求 - 可以下载「postman」或「apipost」来进行「post请求」
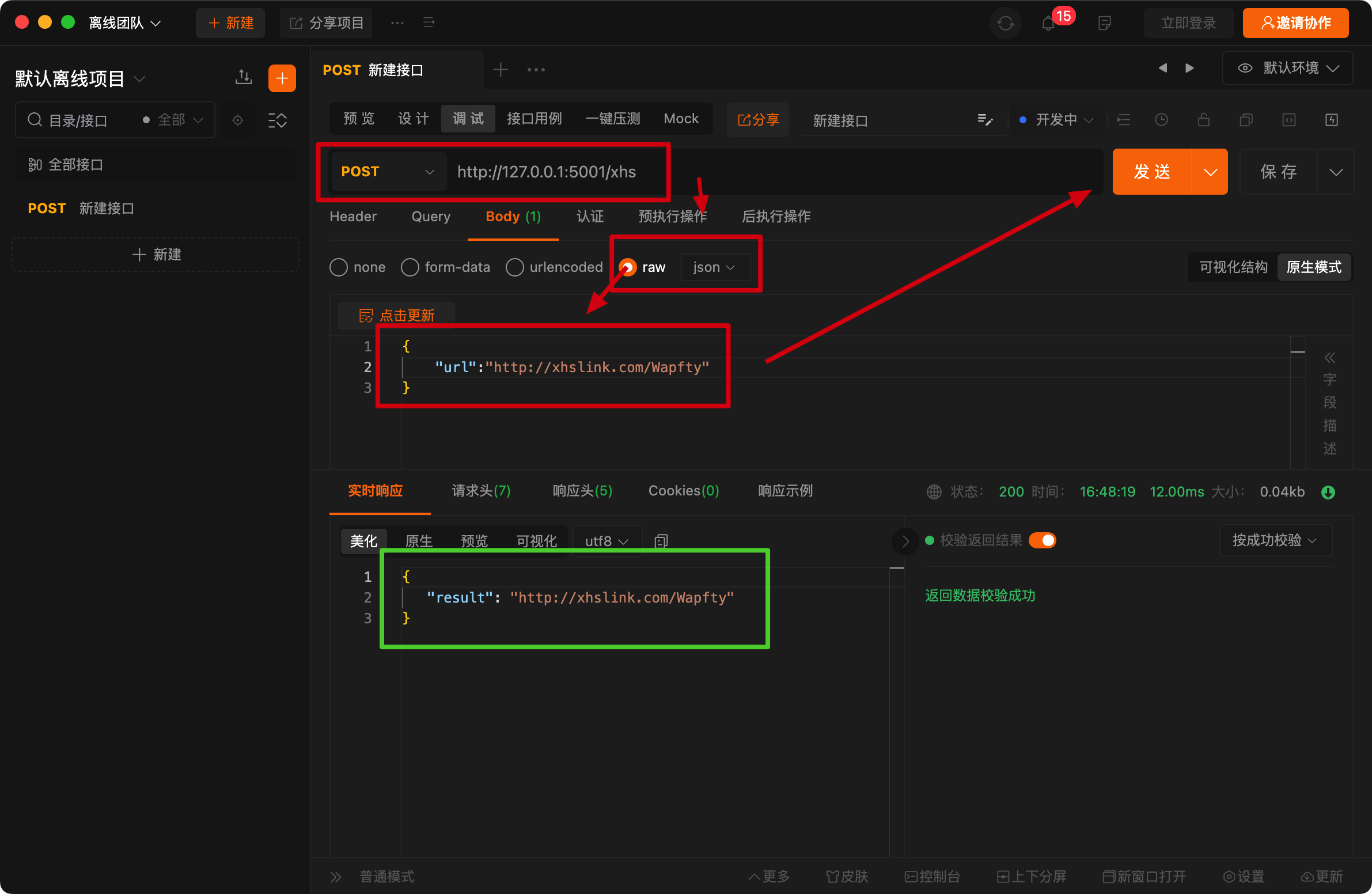
可以看到这上面就是个简单的Python服务,它监听5001端口,然后接受到POST请求,然后把POST请求的JSON数据返回。
我们接下里两个步骤:
- 先暂时用 apipost的「post请求」 来代替手机「快捷指令」发送过来的url
- 我们把python爬取的任务写完:
- 拿到的这个数据去用python爬取「小红书网页版本的链接」
我写了以下代码来获取,如果会python爬虫的小伙伴也可以自己去小红书的网页版看看网页的DOM结构,然后来爬,如果找不到图片链接可以看以下来获取灵感👇
需要注意:这是2024年1月1日的脚本,如果小红书有改动,这个脚本可能就没用了,但是思路不变!!!
from flask import Flask, request, jsonify
import requests
from bs4 import BeautifulSoup
app = Flask(__name__)
headers = headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': 'https://www.xiaohongshu.com/',
# 'Cookie':'' #必要时候带上Cookie
}
@app.route('/xhs', methods=['POST'])
def process_url():
# 获取JSON数据
data = request.json
url = data.get('url')
data = {
'status': 200,
'img':'',
'msg':''
} # 等等要返回的数据
try:
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
html = res.text
soup = BeautifulSoup(html, 'lxml')
# 可以把爬取的网页写下来看看真正爬取到的结构
with open('test.html', 'w', encoding='utf-8') as f:
f.write(str(soup))
# 获取图片名称
img_title_area = soup.find('meta', attrs={'name':'og:title'})
img_title = img_title_area['content']
# 获取图片链接
img_area = soup.findAll('meta', attrs={'name':'og:image'})
num = 0
img_data = []
for i in img_area:
# 给图片1号 2号.... 加一下后缀~
num+=1
img_name = img_title + '.png'
if len(img_area) > 1 and num == 2:
img_name = img_title + '-' + str(num) + '.png'
img_url = i.get('content')
### 【这一部分是本地下载,如果你只是想下载到手机,可以去掉这段】
try:
img_res = requests.get(img_url,headers=headers)
img_res.encoding = 'utf-8'
with open('img/'+img_name, 'wb') as f:
f.write(img_res.content)
except:
continue
### 【👆 这就是这7行.. 记得如果要使用,在当前目录新建一个叫 img 的文件夹哦😁】
##【下面就是整理一下数据~】
img = {
'name':img_name,
'url':img_url
}
img_data.append(img)
data['img'] = img_data
data['status'] = 200
data['msg'] = '✅ 获取成功'
except:
data = {
'status': 403,
'img': '',
'msg': '❌ 获取失败... 程序出错'
} # 等等要返回的数据
# 返回结果
return jsonify(data)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5001)
好了我们本地试一下:
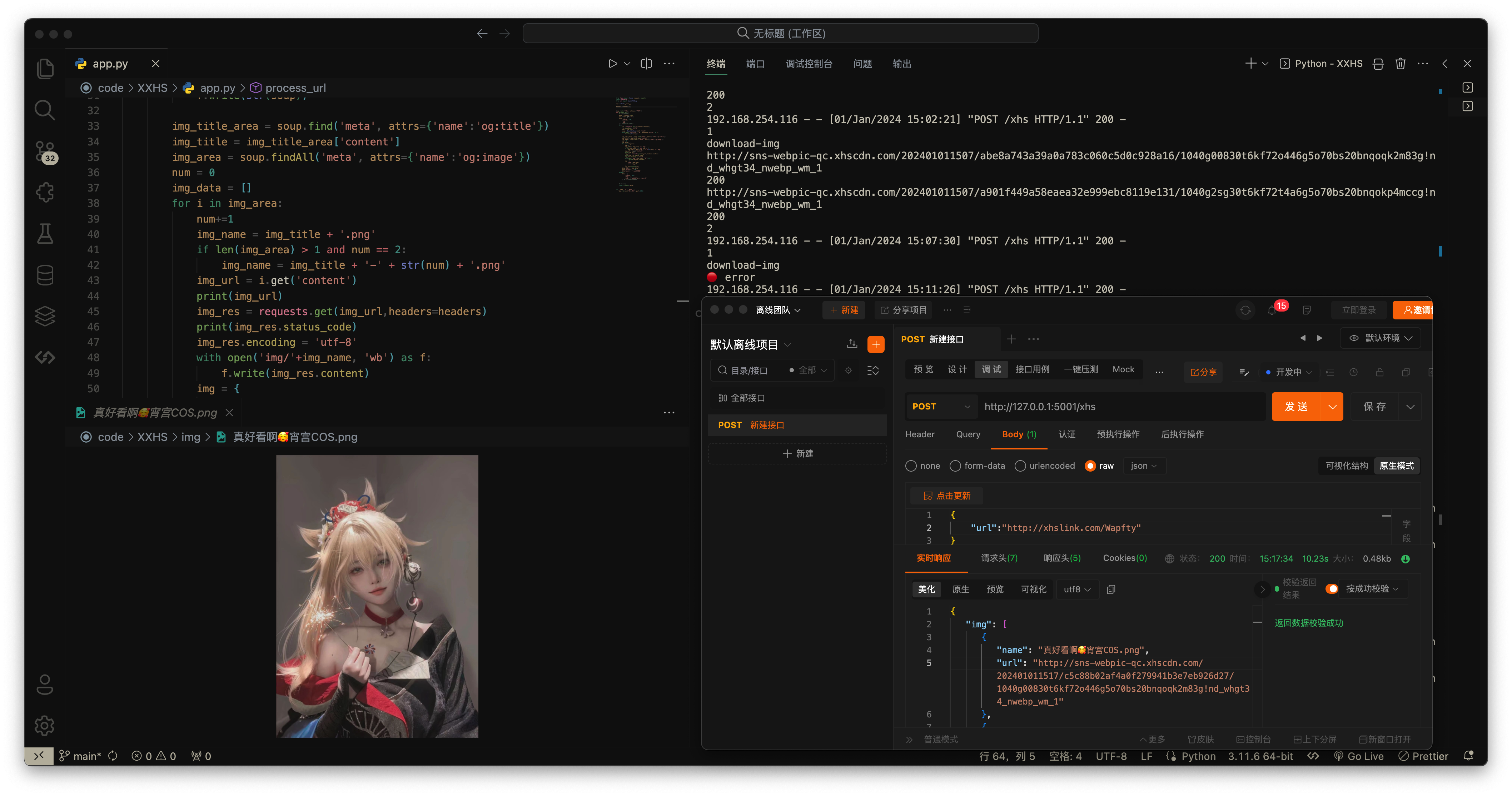
好!很好! 非常好! 🎉
其实思路只要正确,一般都不会出错的…
接下来我们不就是用手机的「快捷指令」来发送「小红书的网页链接」到这个接口就可以了吗?!对吧!嘻嘻😁
接下来我们去「快捷指令」处操作吧👇
「快捷指令」发送 URL 到 「Flask」
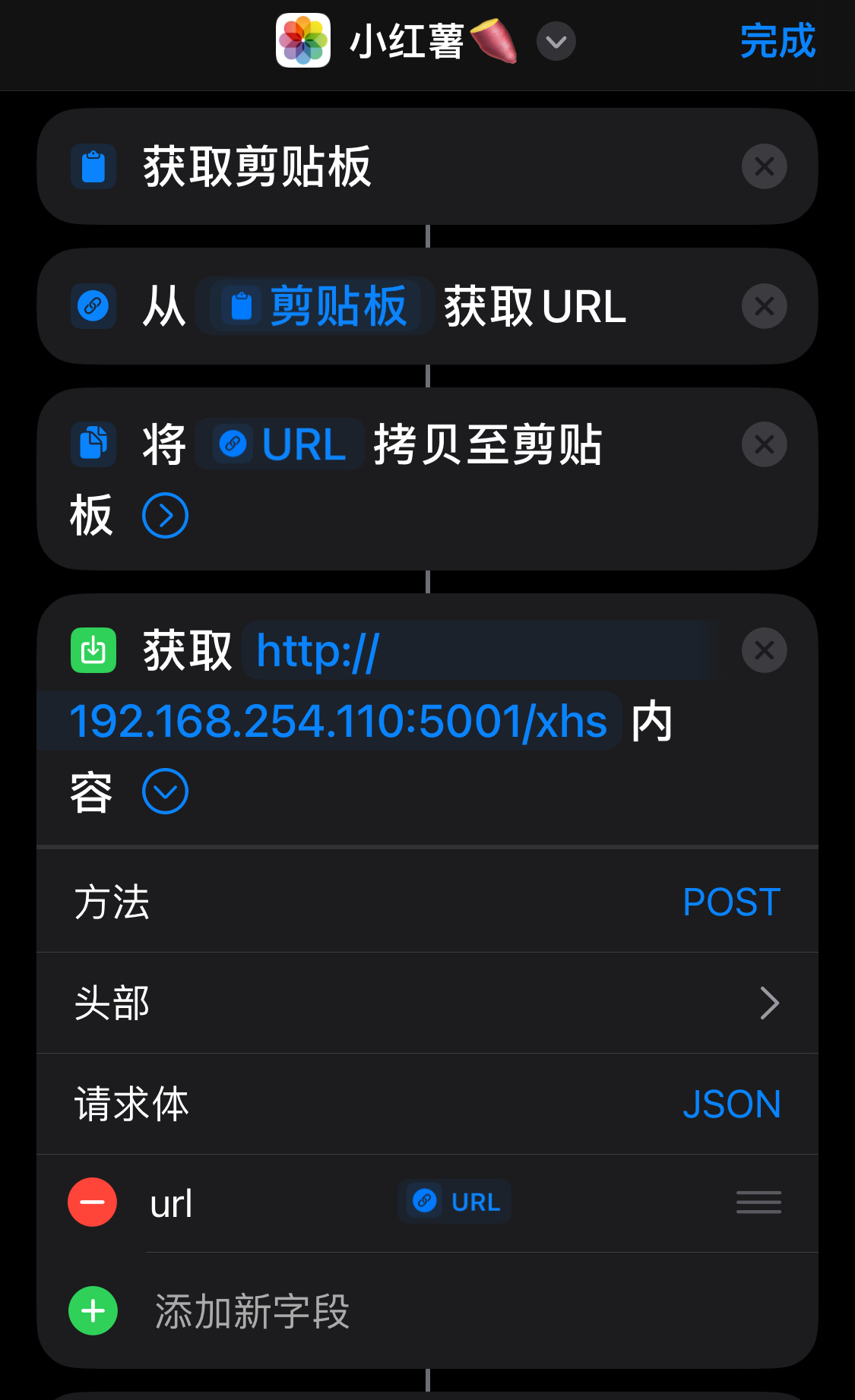
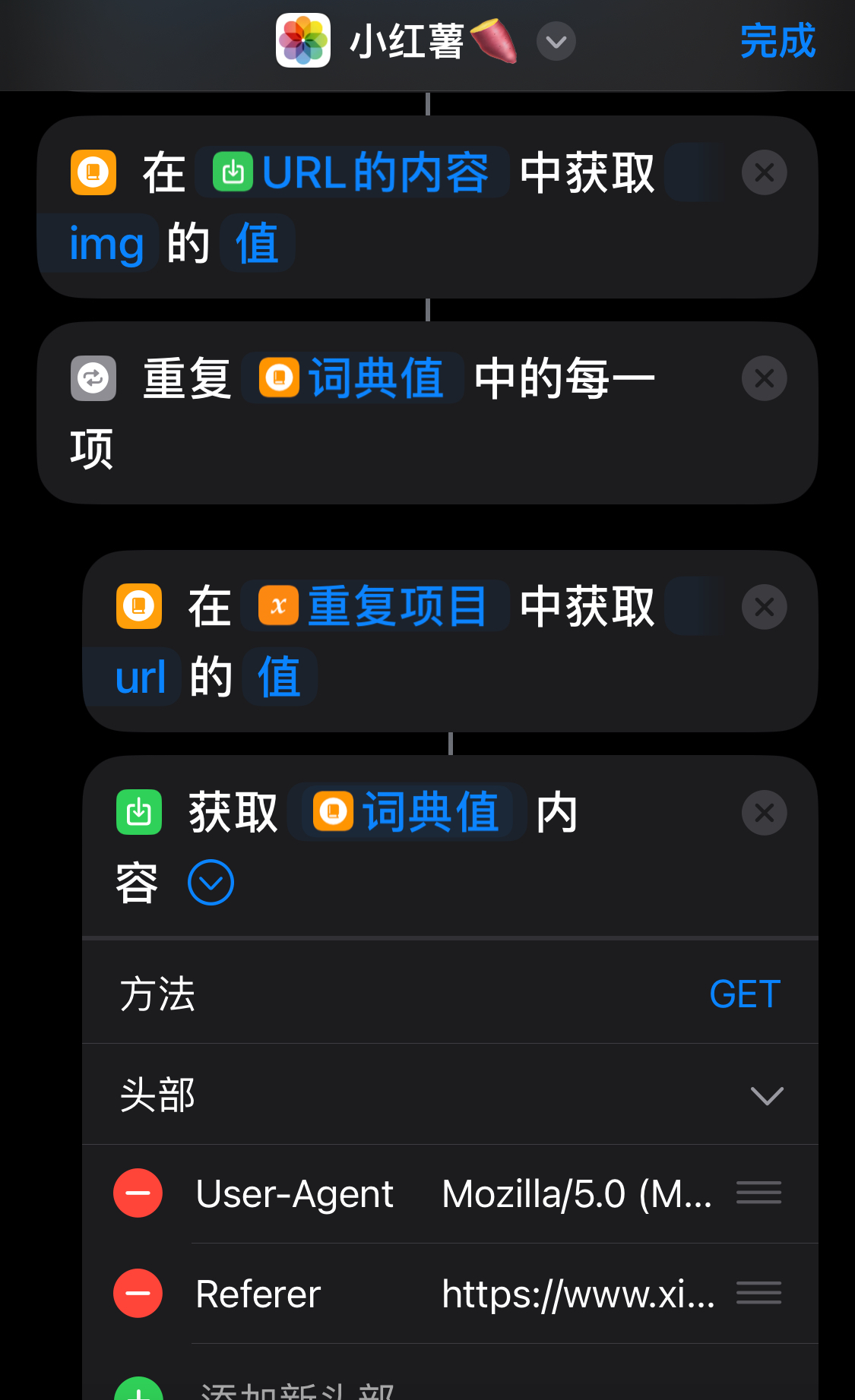
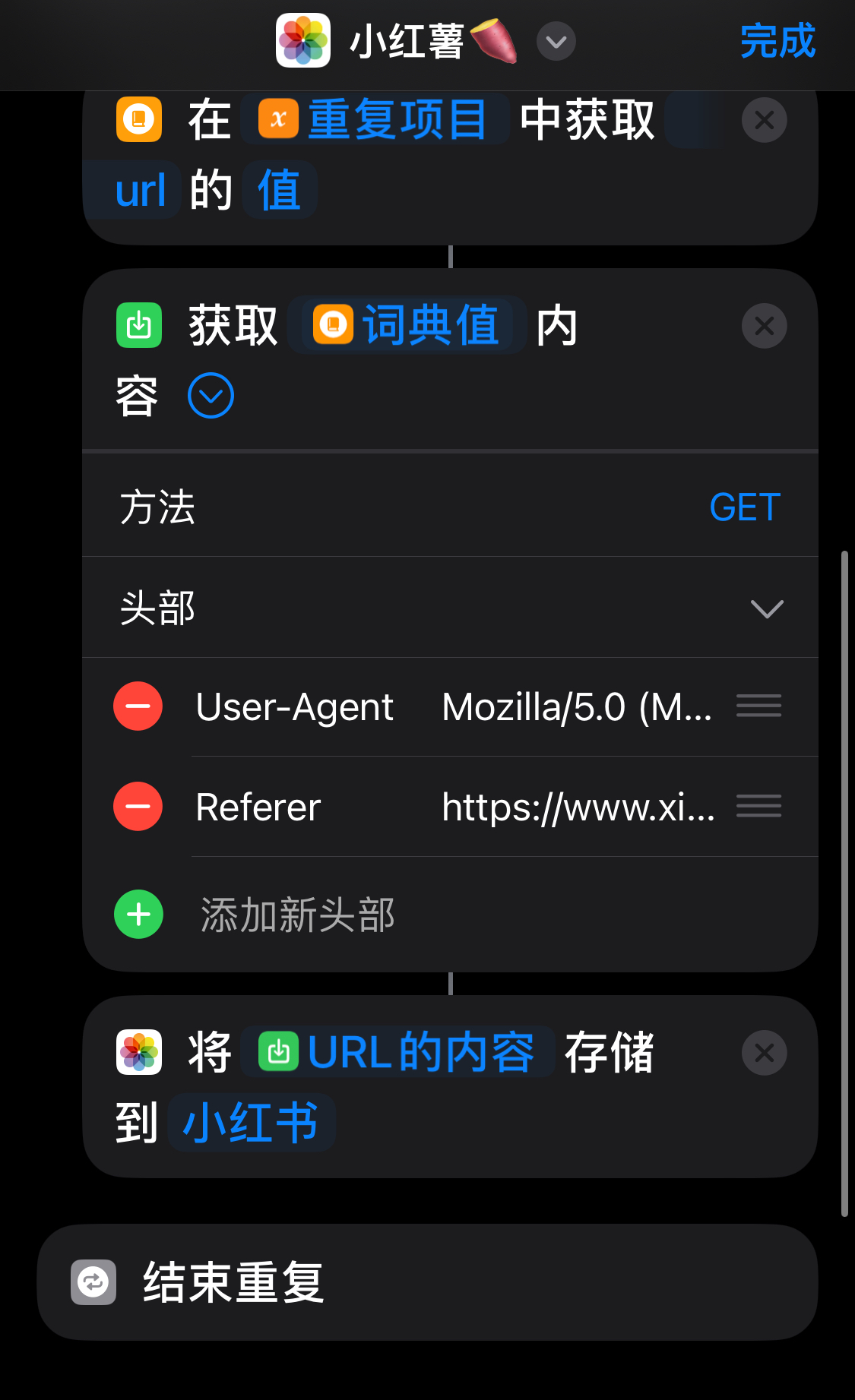
没错! 跟着这样操作吧,相信聪明的你即使不用我讲解也能看得懂!
- 词典:就是 Json -
{ } - 重复:就是 List -
[ ]



注意注意⚠️ 请不要把这些技术用在不好的地方,例如涉及版权问题和人文道德问题,技术无罪,但是别爬取人家小姐姐的照片去干坏事啊喂!😡
最后你肯定还是有很多疑问,例如:
Q1:局域网才能用?
是的,如果你想在家以外的地方也能使用上这项服务,要么就买个便宜的服务器,然后把这个服务部署在服务器上。 或者学习一下内网穿透把家里的服务暴露到外网,这样就可以在外网访问到这个服务了。
Q2:占用终端窗口?
服务一启动,占用终端窗口,不能关掉,很不优雅?!
没事,这个可以使用像gunicorn之类的WSGI HTTP服务器,还可以使用systemd来管理服务。这个技术后面会讲解,使用systemd管理服务,可以让服务开机自启,还可以管理服务的重启、停止等。而且不会有碍眼的终端窗口在你的屏幕上,它会在后台静默运行着。灰常优雅~
Q3:脚本优化问题
你这些脚本看起来很随便喔,比如我要是不复制url 给你,你不就报错了…
程序可以后面继续完善,甚至可以下载视频,或者区分出谁家的网页,抖音的视频也可以下载下来。
好了,本期分享就到这里了,最近写的文章是越来越多了,但是也真的是忙,我已经很久没打游戏了,希望以后会有多点时间可以学习和打游戏吧~ 下期再见咯👋